【元來(lái)如此】第三章——Mixtral 8x7B深入挖掘,改變遊戲規則的AI模型!

正文(wén)共:2285字 8圖
預計(jì)閱讀時(shí)間:6分鐘(zhōng)
作(zuò)者:思成
軟件生态中心·應用(yòng)平台部·模型應用(yòng)組
Mixtral 8x7B是由Mistral AI在23年10月發布的一種稀疏混合專家混合模型(SMoE),在多項Benchmark測試中效果優于LLaMa2 70B和(hé)GPT3.5。基于Mixtral 8x7B得到(dào)的Mixtral 8x7B-Instruct指令跟随模型在Human Evaluation榜單上(shàng)超過了(le)GPT-3.5 Turbo、Claude-2.1、Gemini Pro和(hé)LLaMA 2-Chat 70B。同時(shí),這(zhè)2個模型免費供學術和(hé)商業使用(yòng)。
Mixtral 8x7B同樣是一個Decoder Only的模型,區(qū)别于傳統的LLaMA等模型,FNN層由8個前饋神經網絡(Expert)組成。如果我們從(cóng)某一個Token的視(shì)角看(kàn),這(zhè)個Token會(huì)經過其中的2個前饋神經網絡或者說Expert。也(yě)就是說雖然整個模型的參數量是46B,但(dàn)是在推理(lǐ)過程中激活的參數隻有13B。
剛剛提到(dào)對(duì)于1個Token隻有2個Expert被激活,這(zhè)個機制是通過路由網絡(Router)來(lái)控制。在Mixtral 8x7B中路由網絡由1個前饋神經網絡組成。整個混合專家層模型結構以及數學表示如圖1[1]所示。
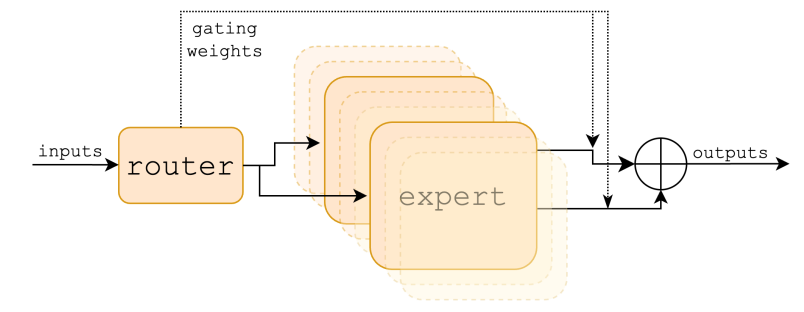
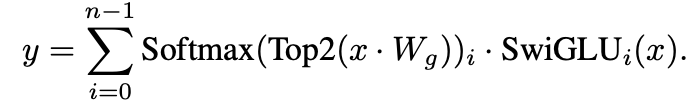
圖1 混合專家層
雖然Mixtral 8x7B在推理(lǐ)過程中同一時(shí)間激活的參數隻有13B左右,但(dàn)是爲了(le)保證推理(lǐ)性能(néng),還是需要将全部參數(46B)讀入顯存,以A100-80GB爲例,對(duì)于46B的參數的模型,按照FP16精度來(lái)估算(suàn),參數預期占用(yòng)92GB顯存。以batch爲20、Context length=1024、Generate length=1024來(lái)看(kàn)、KV Cache需要的顯存爲20GB[2] ,也(yě)就是說理(lǐ)想态下(xià)(不考慮顯存碎片,Activate output),至少需要2張A100-80GB完成推理(lǐ)。
多卡的LLM推理(lǐ)場景下(xià),我們将LLM模型結構抽象爲Attention和(hé)FFN兩部分,因爲Mixtral 8x7B模型不涉及Attention部分的模型結構改進,所以Attention部分的并行方案[3]遵照标準方案,如圖2所示。
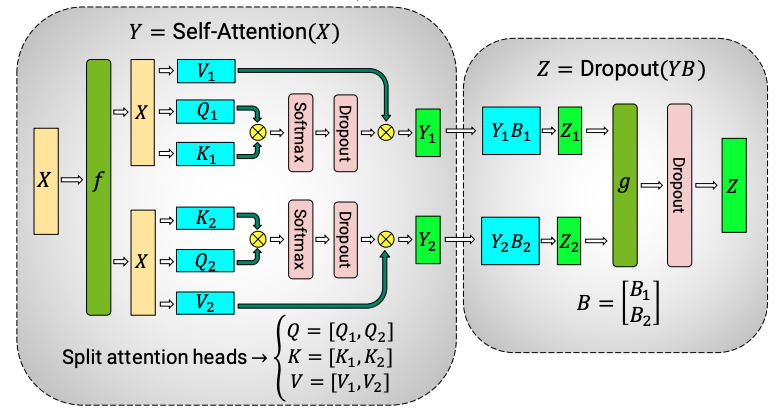
圖2 Attention層模型并行方案
接下(xià)來(lái)我們來(lái)看(kàn)混合專家層的并行方案設計(jì)。

數據并行
Mixtral 8x7B 2張卡的數據并行方案如圖3所示。可以看(kàn)到(dào)Expert 1-8的參數在每張GPU上(shàng)都被拷貝了(le)一份,對(duì)于不同的輸入,每張卡單獨進行推理(lǐ)。這(zhè)樣的方案不需要在Expert之間進行額外(wài)的通信開(kāi)銷。但(dàn)是顯而易見的問題是顯存開(kāi)銷大(dà);同時(shí),每一張卡的輸入是一個完整的任務,需要在每張卡任務的Batch和(hé)序列緯度進行MASK,從(cóng)而拆解爲不同的子任務,并單獨完成模型推理(lǐ),最後通過All Gather通信再次在每張卡上(shàng)還原爲完整的任務。
從(cóng)上(shàng)述過程中,可以看(kàn)到(dào)算(suàn)力除了(le)特殊情況(Batch=1, Sequence length=1)之外(wài)并沒有浪費,同時(shí)在保證Batch * Sequence length % GPU_CNT== 0的情況下(xià)也(yě)不存在負載均衡問題。
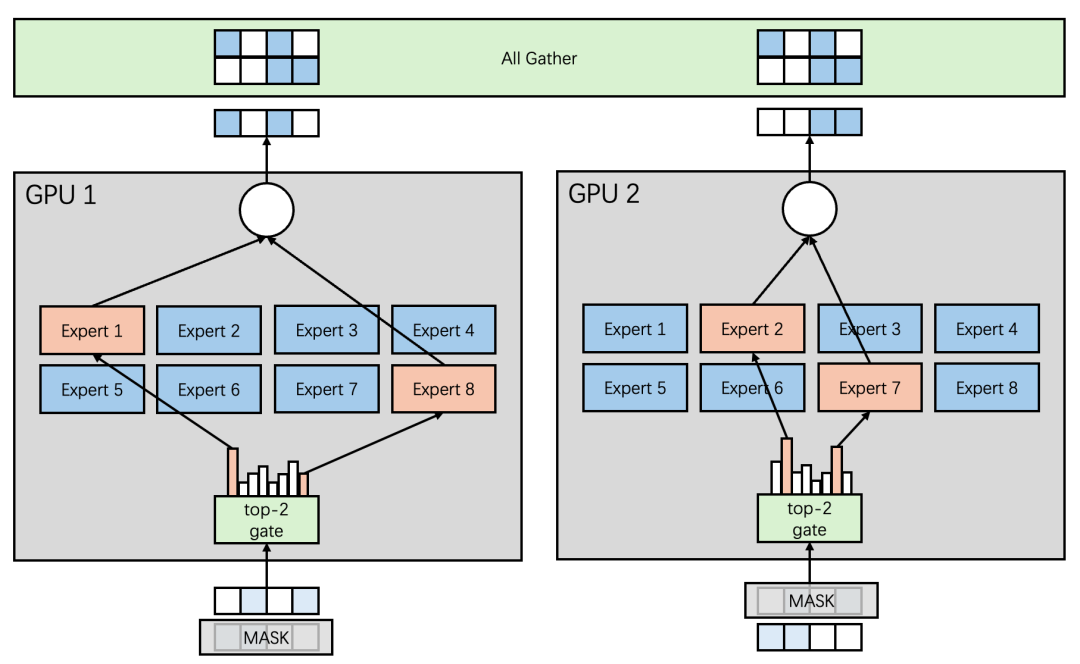
圖3 Mixtral 8x7B 2卡并行推理(lǐ)-數據并行方案
專家并行
從(cóng)數據并行的方案中可以看(kàn)到(dào),最大(dà)的問題是因爲每張卡都需要保留所有的Expert帶來(lái)的顯存浪費。既然這(zhè)樣,爲什(shén)麽不每張卡隻保留若幹Expert呢(ne)?專家并行就這(zhè)樣被提出了(le)。如圖4所示。
可以看(kàn)到(dào)Expert 1-4被分配到(dào)了(le)GPU 1上(shàng),Expert 5-8被分配到(dào)了(le)GPU 2上(shàng),很(hěn)好(hǎo)的解決了(le)顯存開(kāi)銷問題;但(dàn)是同時(shí)引入了(le)All2All通信(圖4中紅(hóng)線)。和(hé)數據并行方案類似,每一張卡的輸入是一個完整的任務,需要在每張卡任務的Batch和(hé)序列緯度進行MASK,從(cóng)而拆解爲不同的子任務,每個GPU上(shàng)的子任務将各自(zì)的任務發送到(dào)對(duì)應的Expert上(shàng)完成推理(lǐ),之後再發送回自(zì)身所屬的GPU,最後通過All Gather通信再次在每張卡上(shàng)還原爲完整的任務。
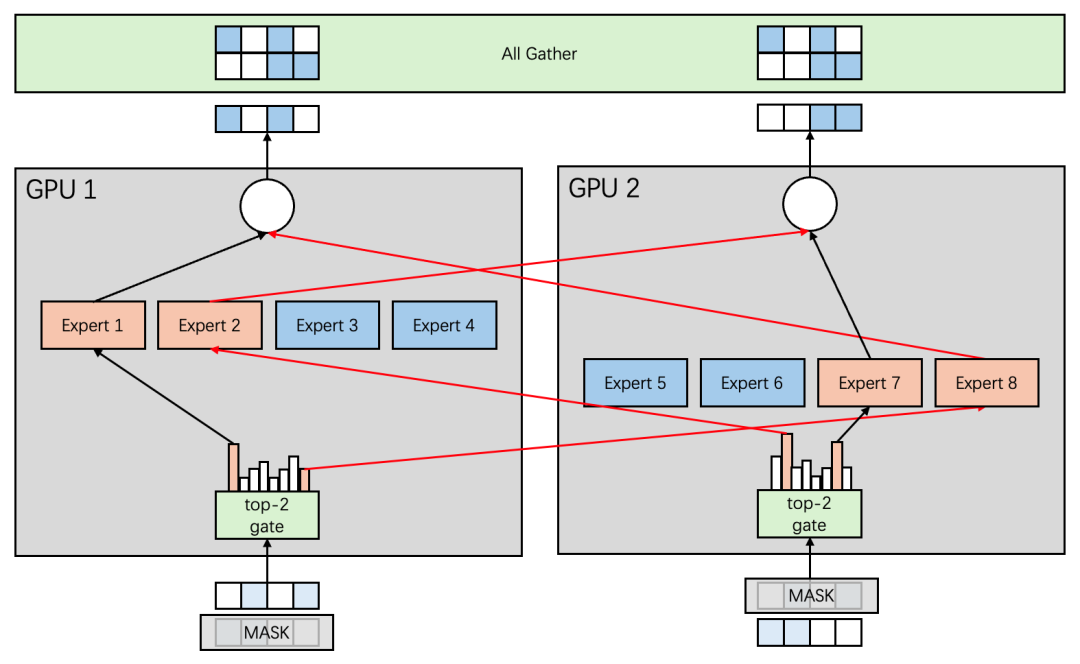
圖4 Mixtral 8x7B 2卡并行推理(lǐ)-專家并行方案
另外(wài),圖4中的例子是一個理(lǐ)想态,Expert的激活剛好(hǎo)是每張卡激活2個Expert。但(dàn)因爲每個Token實際激活哪個Expert是不确定的,考慮更一般的情況如圖5所示。可以看(kàn)到(dào)這(zhè)時(shí)候GPU 1上(shàng)激活了(le)3個Expert,GPU 2上(shàng)激活了(le)1個Expert,也(yě)就是說專家并行是存在負載不均衡的。另外(wài)考慮Batch=1的推理(lǐ)場景,Generate階段同一時(shí)間隻會(huì)有1張GPU卡被激活,造成算(suàn)力的浪費。
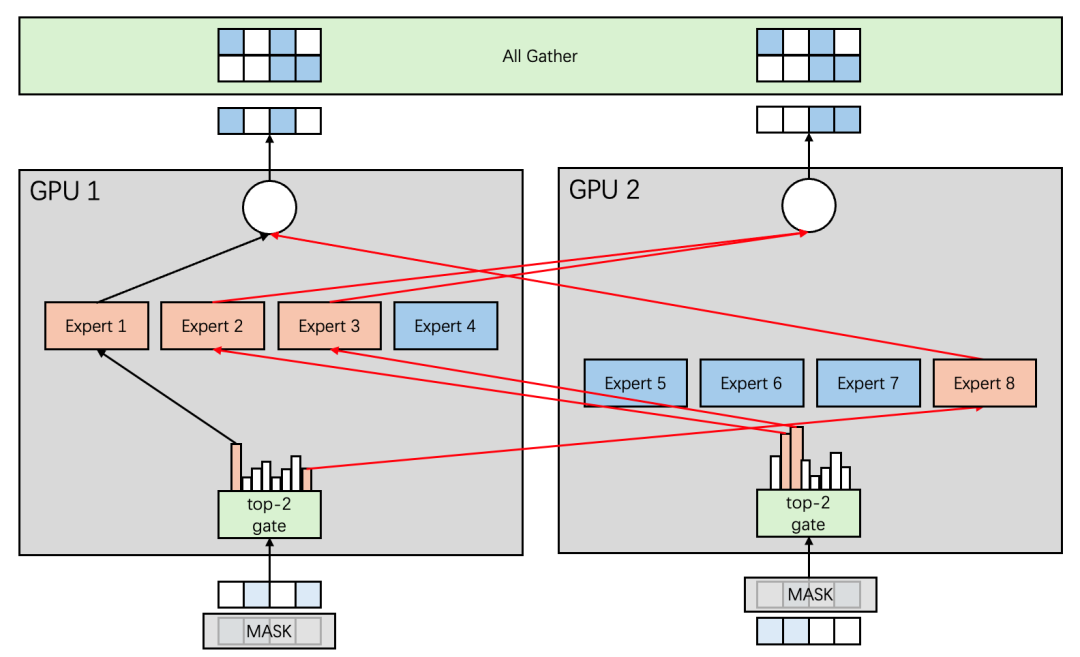
圖5 Mixtral 8x7B 2卡并行推理(lǐ)-專家并行方案
爲了(le)進一步驗證Mixtral 8x7B的負載均衡問題,我們随機挑選了(le)若幹問題,并分别統計(jì)了(le)32層的Expert激活情況,如圖6(Heatmap)所示。
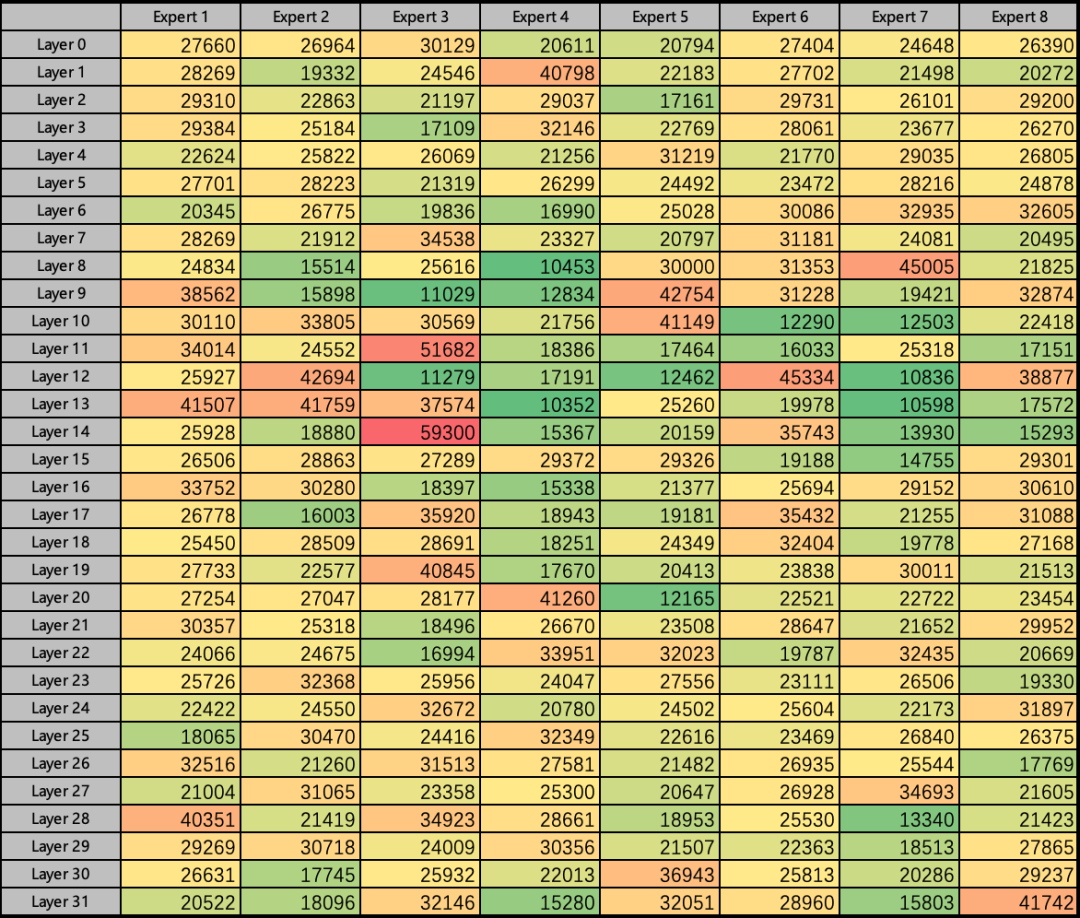
圖6 Mixtral 8x7B 不同層Expert激活情況
從(cóng)負載均衡角度,全局256個專家中可以明(míng)顯看(kàn)到(dào)Layer 14 的Expert 3 是最經常被路由到(dào)的,而Layer 13的Expert 4是最少被路由到(dào)的,前者比後者要勤奮5.72倍。從(cóng)每層的8個Expert橫向對(duì)比也(yě)可以發現(xiàn),Layer 8 中最勤奮的Expert比最懶惰的Expert多工(gōng)作(zuò)4.3倍。

模型并行
爲了(le)解決數據并行和(hé)專家并行帶來(lái)的若幹問題,我們讨論模型并行的方案,如圖7所示。将Expert按照Embedding維度縱向切分。每張卡保留所有Expert的一個切片。
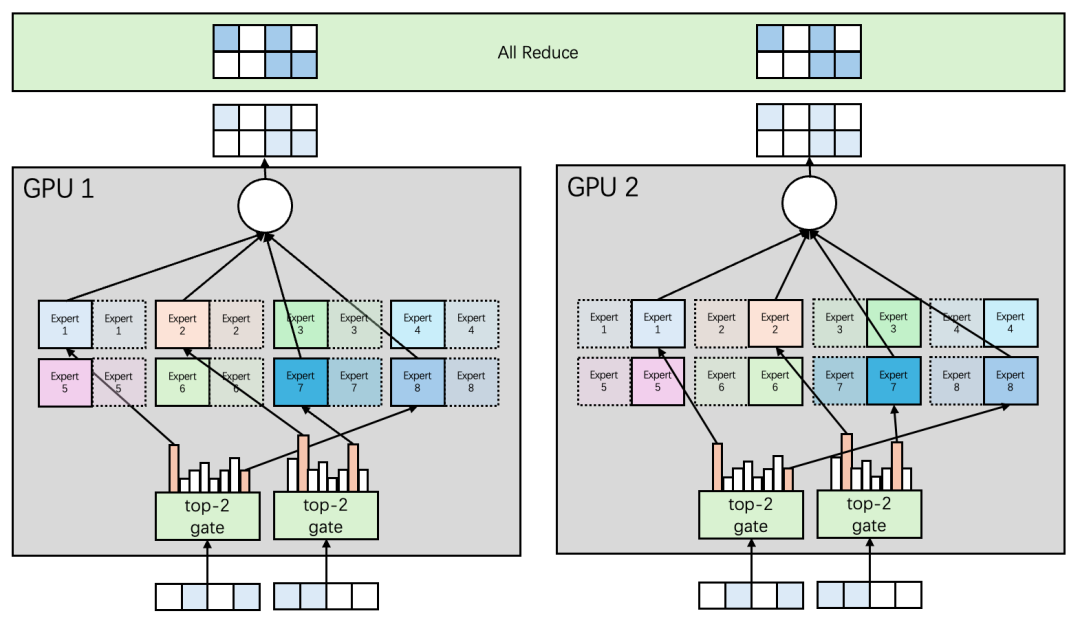
圖7 Mixtral 8x7B 2卡并行推理(lǐ)-模型并行方案
GPU 1上(shàng)保留了(le)Expert 1-8的部分參數(左側實線),GPU 2上(shàng)保留了(le)Expert 1-8的另外(wài)一部分參數(右側實線)。同時(shí)在輸入側不需要按照Rank進行MASK操作(zuò),每張卡處理(lǐ)全部的數據,并根據各自(zì)的參數切片得到(dào)輸出的切片,最後通過All Reduce通信将輸出融合。
從(cóng)上(shàng)述的過程中,可以看(kàn)到(dào),模型并行的方案不存在負載均衡問題,同時(shí)受到(dào)的約束相對(duì)來(lái)說最少(Dimension % Rank == 0),同時(shí)不會(huì)引入額外(wài)的通信開(kāi)銷。
綜上(shàng),我們發現(xiàn)基于稀疏混合專家混合模型的LLM推理(lǐ)主要限制因素包括顯存、通信、計(jì)算(suàn)3方面。而數據并行的方式在顯存方面存在巨大(dà)的劣勢,模型并行和(hé)專家并行在顯存方面的顯存占用(yòng)一緻。所以問題進一步簡化爲通信和(hé)計(jì)算(suàn)兩方面。

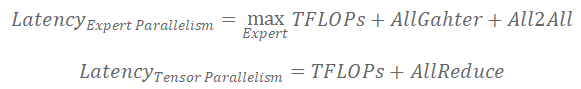
太初元碁Tecorigin基于上(shàng)述分析,深度優化了(le)Mixtral 8x7B模型推理(lǐ),在Batch size=1,Context length=1024,Generate length=1024下(xià),端到(dào)端推理(lǐ)速度百分位(越大(dà)越好(hǎo))對(duì)比基于GPU A800 * 2硬件的不同開(kāi)源LLM推理(lǐ)框架效果如圖8所示。
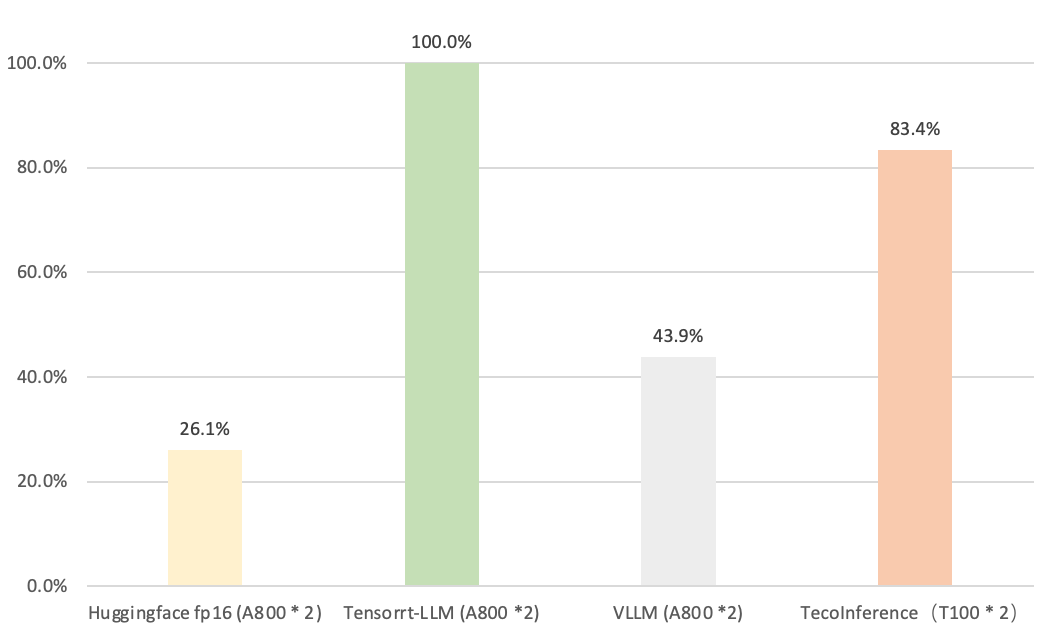
圖8
Mixtral 8x7B 2卡并行推理(lǐ)TecoInference端到(dào)端速度對(duì)比
至此,本文(wén)簡要介紹了(le)Tecorigin在Mixtral 8x7B模型推理(lǐ)上(shàng)的探索。未來(lái),期待更多的大(dà)模型技術跟大(dà)家一起分享、交流、讨論。
參考文(wén)獻
[1] [2401.04088] Mixtral of Experts (arxiv.org)
[2] 【元來(lái)如此】第二章——打破序列長度限制,讓無限Token成爲可能(néng)!(qq.com)
[3] [2104.04473] Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM (arxiv.org)
上(shàng)一條新聞融合發展·智算(suàn)新篇 | 太初元碁Tecorigin與華信設計(jì)院…