【元來(lái)如此】第二章——打破序列長度限制,讓無限Token成爲可能(néng)!

正文(wén)共:1929字 6圖
預計(jì)閱讀時(shí)間:3分鐘(zhōng)
作(zuò)者:思成
軟件生态中心·應用(yòng)平台部
“
此前,我們在【元來(lái)如此】第一章——大(dà)模型技術 · 起航&推理(lǐ)篇中對(duì)大(dà)模型推理(lǐ)技術做了(le)一些(xiē)基礎介紹。
還沒有關注的同學快(kuài)來(lái)補課!

(點擊圖片,即可跳轉閱讀)
目前主流大(dà)模型推理(lǐ)框架比如vLLM、FasterTransformer+Triton Server、TGI(Text Generation Inference)等在Latency(時(shí)延)、Throughput(吞吐)、Utilization(利用(yòng)率)、易用(yòng)性等方面各有優劣。但(dàn)是當前主流大(dà)模型隻能(néng)生成有限長度的文(wén)本(比如LLaMA 2 7B模型的限制是2048個Tokens),剩餘的部分會(huì)被截斷掉。
本文(wén),針對(duì)以上(shàng)長序列問題,我們将介紹Tecorigin在無限長序列推理(lǐ)生成上(shàng)的一些(xiē)探索和(hé)努力。
我們基于StreamingLLM[1]算(suàn)法提出了(le)inference-infinitely,并在Teco-Inference-Engine(推理(lǐ)引擎框架)上(shàng)支持了(le)這(zhè)種算(suàn)法,從(cóng)而賦予了(le)大(dà)模型無限長度生成的能(néng)力。我們在Baichuan2-7B-Chat上(shàng)進行了(le)驗證。
StreamingLLM
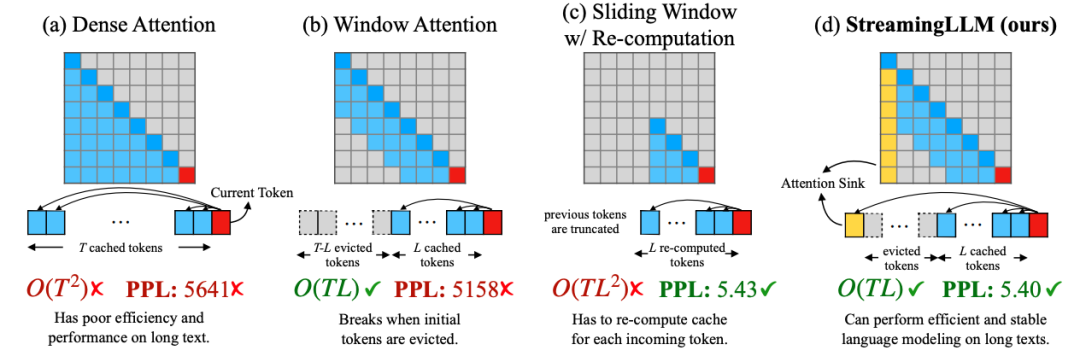
圖1 StreamingLLM和(hé)其他(tā)方法示意圖,引用(yòng)自(zì)[1]
1(a)
如圖1(a)所示,是Transformer模型最基礎的Attention形式,這(zhè)種Dense的方式在生成第T個Token的時(shí)候需要關注前面0到(dào)T-1個Token,做全局的注意力,這(zhè)意味着0(T2)的時(shí)間複雜(zá)度和(hé)不斷增加的KV cache顯存占用(yòng)。
1(b)
1(b) 其改進版本,一種Window Attention,這(zhè)種方式在生成第T個Token的時(shí)候隻需要關注前面L個Token即可,這(zhè)種方式獲得了(le)0(TL)的時(shí)間複雜(zá)度,以及可控的KV cache顯存占用(yòng),但(dàn)是也(yě)帶來(lái)了(le)斷崖式的效果下(xià)降。
1(c)
1(c) 另一種改進版本,稱作(zuò)Sliding Window Attention,需要在每次計(jì)算(suàn)的時(shí)候重新計(jì)算(suàn)長度爲L的KV cache,這(zhè)種方法會(huì)有比較好(hǎo)的模型效果,但(dàn)是也(yě)帶來(lái)了(le)性能(néng)的損失。
1(d)
1(d) StreamingLLM的做法,理(lǐ)解起來(lái)很(hěn)簡單,在1(b)的基礎上(shàng),保留一些(xiē)初始的Token。通過這(zhè)樣的方式即有0(TL)的時(shí)間複雜(zá)度,同時(shí)也(yě)取得了(le)比較好(hǎo)的模型效果。

StreamingLLM的方法到(dào)底爲什(shén)麽生效呢(ne)?其實之前在Lost in the Middle [2] 中的研究已經發現(xiàn),Dense Attention的方式其注意力會(huì)集中在序列中的頭和(hé)尾兩個部分,對(duì)于中間Token的Attention會(huì)比較弱。
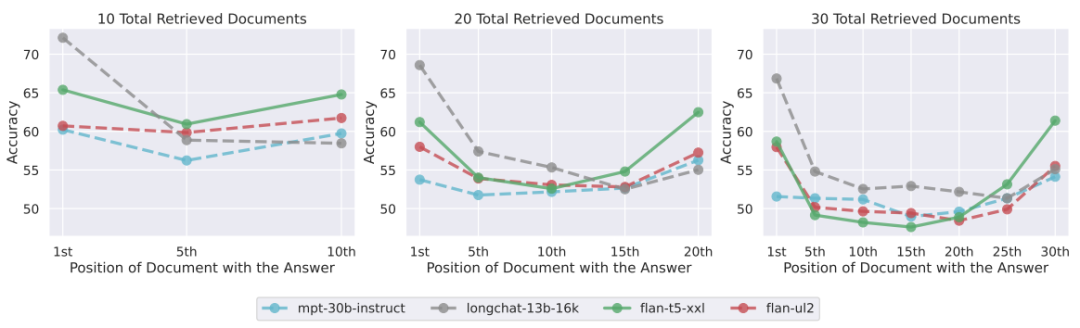
圖2 lost in the middle引用(yòng)自(zì)[2]
這(zhè)種現(xiàn)象在StreamingLLM中也(yě)得到(dào)了(le)進一步的驗證:
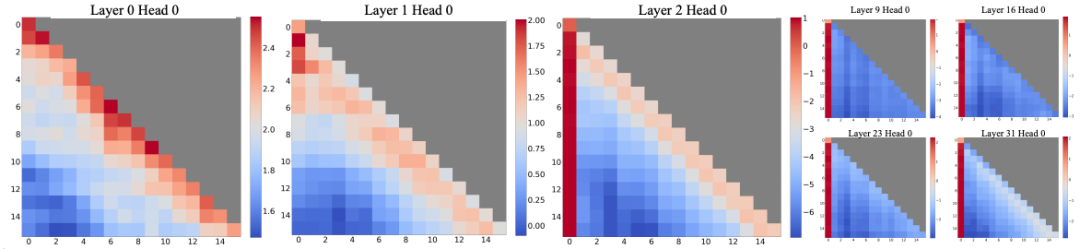
圖3 除去0和(hé)1層的Head之外(wài),其他(tā)層都重點關注頭部部分,引用(yòng)自(zì)[1]
論文(wén)中也(yě)對(duì)此進行了(le)一定解釋:要麽是開(kāi)始的Token在模型推理(lǐ)過程中扮演着重要的語義信息,要麽是模型出于某種原因,導緻了(le)對(duì)于這(zhè)些(xiē)位置的歸納偏置,即bias。之後論文(wén)通過實驗進一步驗證了(le)後者更可能(néng)是主要原因。
基于上(shàng)面的現(xiàn)象,StreamingLLM中保留了(le)一定的初始Token,通過這(zhè)種Attention sink的方案穩定Attention計(jì)算(suàn)。之後通過Rolling KV的方式保留一定數量的最新Token。
如圖4所示。
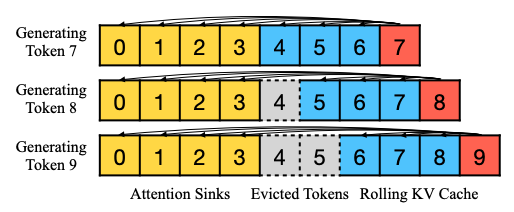
圖4 Streaming LLM中的KV cache方案,
引用(yòng)自(zì)[1]
到(dào)此爲止,我們從(cóng)介紹了(le)StreamingLLM的來(lái)龍去脈,下(xià)面讓我們深入細節,進一步思考。
KV cache
上(shàng)一節我們多次提到(dào)了(le)KV cache這(zhè)樣的字眼,簡單說:KV cache是一種在自(zì)回歸大(dà)模型下(xià)的優化方法,該方法通過緩存一定的過去信息(K和(hé)V),用(yòng)于加速當前step模型的推理(lǐ)過程,避免重複計(jì)算(suàn)。
詳細來(lái)看(kàn),如圖5所示:
Step 1:正常的Attention計(jì)算(suàn),之後将K矩陣和(hé)V矩陣的結果緩存下(xià)來(lái)KcacheVcache。
Step 2:根據第一步生成的Token,生成當前step的Qstep/Kstep/Vstep向量(圖5中Step N藍色部分),并将Kstep/Vstep和(hé)第一步生成的KcacheVcache拼接到(dào)一起生成真正的K/V向量,從(cóng)而進行後面的計(jì)算(suàn)。
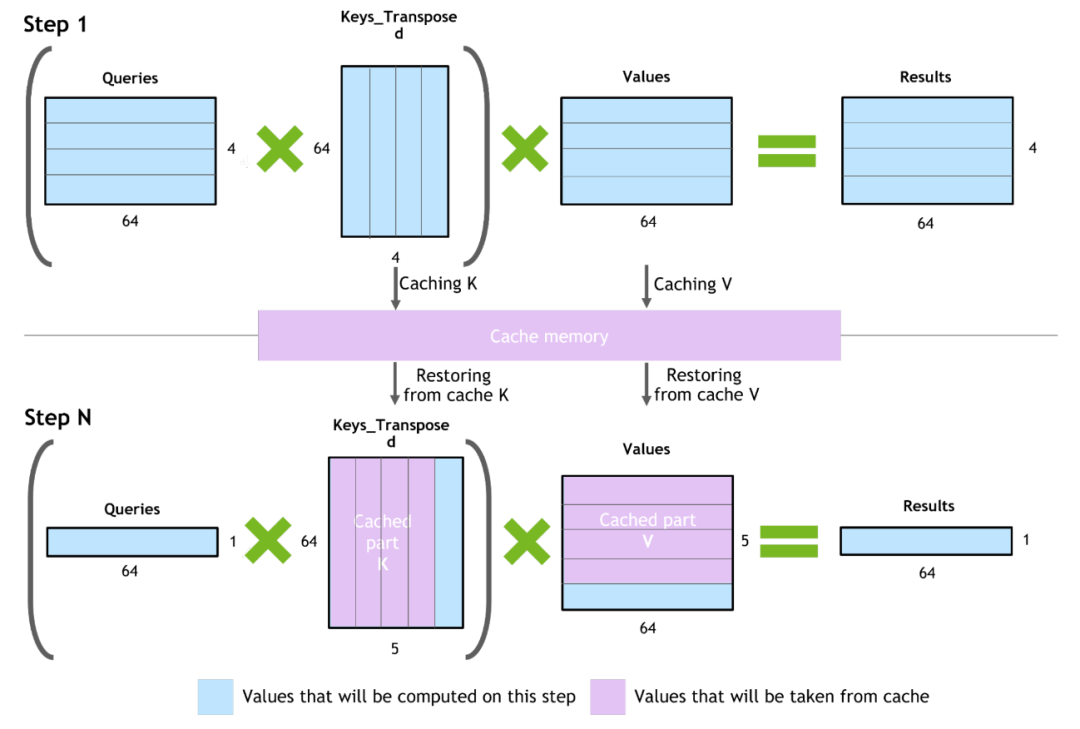
圖5 KV cache機制,引用(yòng)自(zì)[3]
根據這(zhè)樣的原理(lǐ),不難得到(dào)KV cache在顯存中的占用(yòng):2(K+V)*L(模型層數)*B(batch大(dà)小(xiǎo))*S(序列長度)*D(隐層緯度)*2(fp16字節),以LLaMA 2 7B模型爲例帶入得到(dào)2*32*1*4096*4096*2=2GB。
讓我們回想一下(xià)剛剛介紹的StreamingLLM算(suàn)法,當超過最大(dà)長度之後,需要Rolling KV從(cóng)而生成下(xià)一個Token,這(zhè)樣勢必會(huì)造成大(dà)量的KV cache讀寫操作(zuò),給本就訪存密集的推理(lǐ)過程進一步增加大(dà)量額外(wài)訪存量,大(dà)大(dà)降低(dī)推理(lǐ)性能(néng)。
帶着這(zhè)樣的疑問,我們深入StreamingLLM作(zuò)者給出的開(kāi)源實現(xiàn)方案。實際上(shàng),從(cóng)代碼中可以看(kàn)到(dào)是如下(xià)流程:
Step 1:通過設置一個max_gen_len參數控制了(le)本次推理(lǐ)最大(dà)的生成序列長度,并和(hé)當前prompt長度一起重新開(kāi)辟了(le)KV cache最大(dà)的顯存占用(yòng)空(kōng)間。
Step 2:對(duì)KV cache空(kōng)間進行一次整體的Rolling。
Step 3:後續正常推理(lǐ)過程。

可以看(kàn)到(dào)這(zhè)樣的實現(xiàn)方法解決了(le)頻繁的KV cache Rolling帶來(lái)的訪存問題,但(dàn)是在每次問答(dá)中并不能(néng)進行無限長度輸出。
Inference-infinitely
基于上(shàng)述的問題,我們提出了(le)Inference-infinitely,并在Teco-Inference-Engine上(shàng)進行了(le)實現(xiàn),提供了(le)每次問答(dá)都可以無限輸出的能(néng)力。
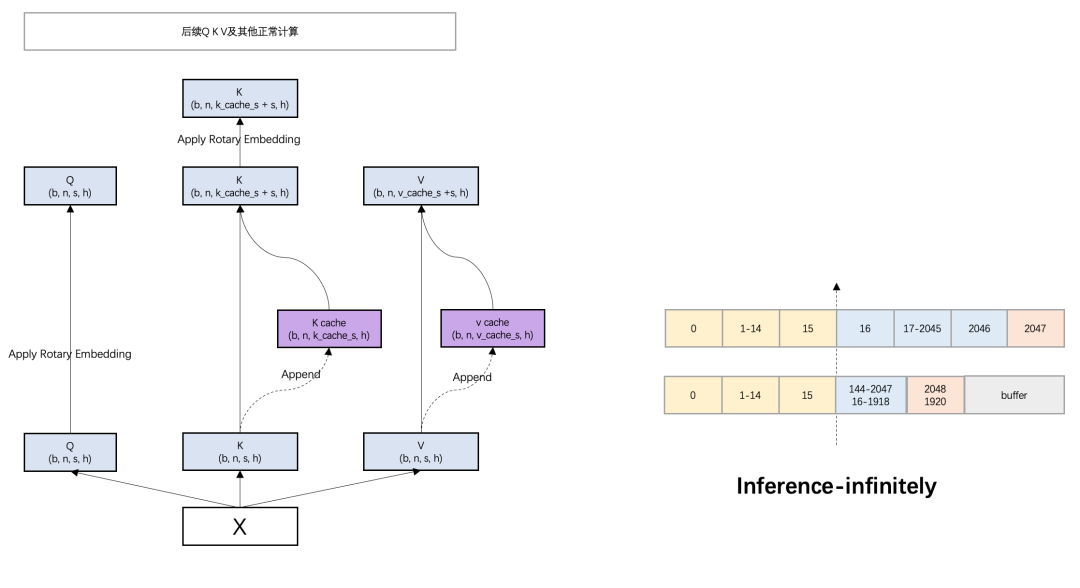
圖6 Inference-infinitely示意圖
圖6中描述了(le)Inference-infinitely的算(suàn)法:
Step 1:保留初始Token(黃色)。
Step 2:當達到(dào)本次輸出的最大(dà)長度之後,将KV cache通過參數W(圖中爲128)進行一次整體滑動(藍色),并生成新的Token(紅(hóng)色)。
Step 3:每滑動一次提供W個Token生成的空(kōng)間(灰色),當buffer填滿之後,再進行Step 2。
通過這(zhè)樣的算(suàn)法,很(hěn)好(hǎo)的解決了(le)上(shàng)述提到(dào)的KV cache Rolling帶來(lái)的頻繁訪存,以及每次問答(dá)的生成都可以有無限的輸出長度,同時(shí)也(yě)保證了(le)模型的推理(lǐ)效果。
至此,本文(wén)介紹了(le)Tecorigin 在大(dà)模型推理(lǐ)——無限長序列生成上(shàng)的一些(xiē)探索和(hé)努力。未來(lái),會(huì)有更多的大(dà)模型技術跟大(dà)家一起分享、交流、讨論。

免費試用(yòng)申請(qǐng)
如果您對(duì)我們的産品感興趣,
可點“http://www.tecorigin.comdeveloper.html ”,進行試用(yòng)申請(qǐng)。
參考文(wén)獻
[1] [2309.17453] Efficient Streaming Language Models with Attention Sinks (arxiv.org)
[2] [2307.03172] Lost in the Middle: How Language Models Use Long Contexts (arxiv.org)
[3] 使用(yòng) FasterTransformer 和(hé) Triton 推理(lǐ)服務器加速大(dà)型 Transformer 模型的推理(lǐ) - NVIDIA 技術博客