【元來(lái)如此】第一章——大(dà)模型技術 · 起航&推理(lǐ)篇(内含産品試用(yòng)申請(qǐng))!




正文(wén)共:3149字 15圖
預計(jì)閱讀時(shí)間:5分鐘(zhōng)
作(zuò)者:思成
軟件生态中心 · 應用(yòng)平台部
前言

LM 語言模型
說到(dào)LLM就不得不提LM(language model語言模型)。語言模型是這(zhè)樣一個模型:對(duì)于一句話(huà)(由詞組成的序列),它能(néng)夠計(jì)算(suàn)出這(zhè)句話(huà)出現(xiàn)的概率。爲了(le)讓模型給出這(zhè)樣的概率P,最簡單的方法就是将其用(yòng)概率論中的方法進行展開(kāi),這(zhè)樣隻要想辦法得到(dào)每一個P(xm|x1x2...xm-1)即可。這(zhè)樣從(cóng)另一個角度來(lái)看(kàn),如果我們可以找到(dào)一個模型:它能(néng)夠計(jì)算(suàn)P(xm|x1x2...xm-1),那麽它就是一個語言模型。

圖1 什(shén)麽是語言模型
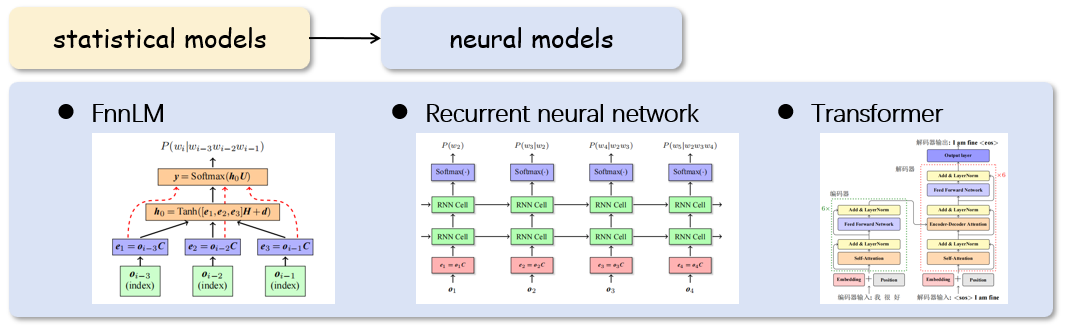
圖2 基于統計(jì)的語言模型和(hé)基于神經網絡的語言模型

LLM 大(dà)語言模型
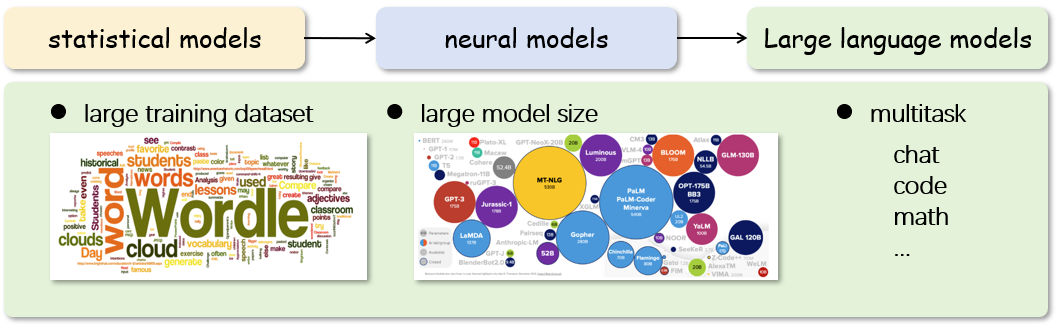
圖3 基于海量數據和(hé)大(dà)參數量的語言模型
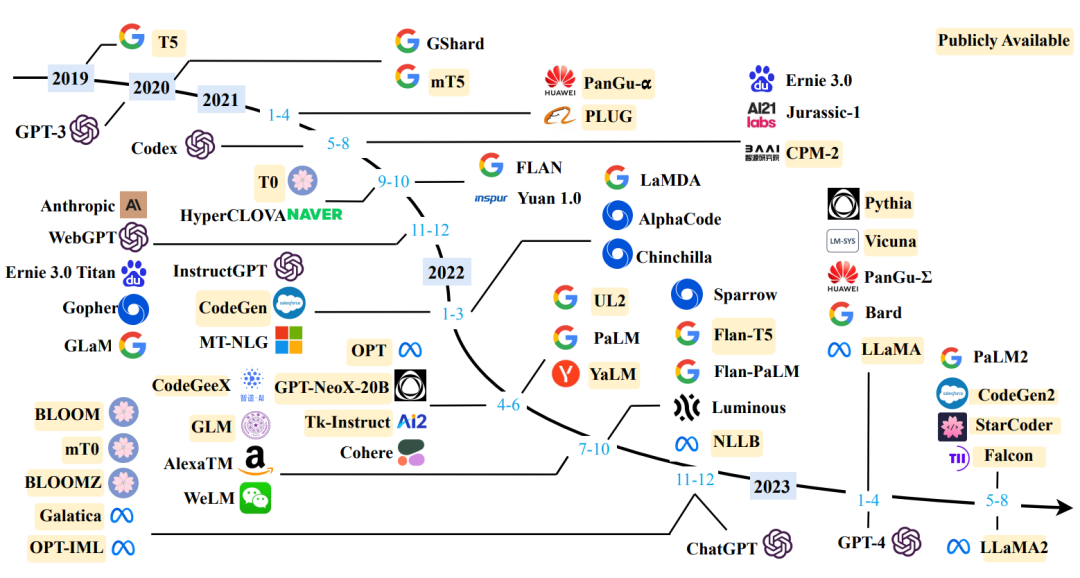
圖4 大(dà)語言模型近3年發展時(shí)間線,引用(yòng)自(zì)[2]
大(dà)模型的應用(yòng)
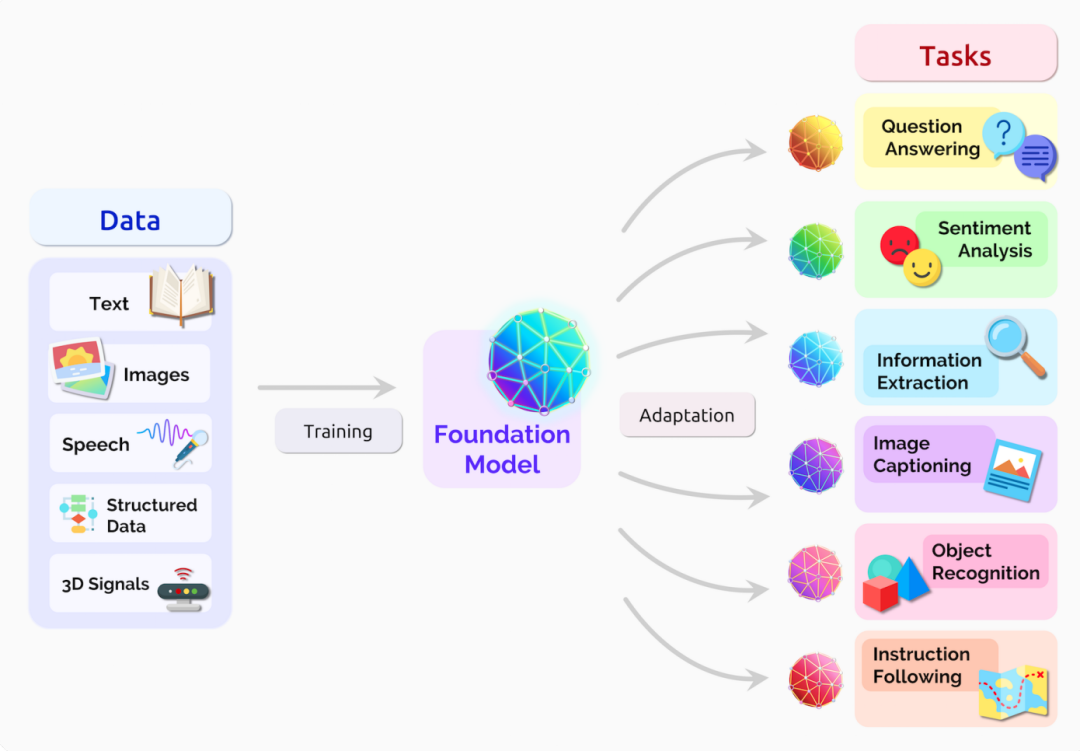
圖5 大(dà)模型應用(yòng)廣泛的下(xià)遊任務,引用(yòng)自(zì)[3]
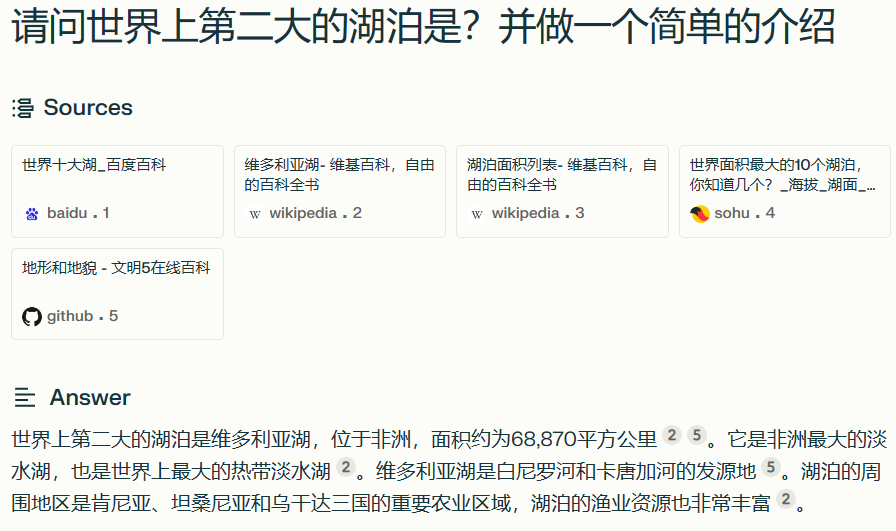
圖6 大(dà)語言模型在搜索問答(dá)中的應用(yòng)
圖7 大(dà)語言模型在輔助編程上(shàng)的應用(yòng)

圖8 大(dà)語言模型在智能(néng)客服場景上(shàng)的應用(yòng)
當大(dà)家都去挖金(jīn)礦時(shí),應該去賣鏟子。如果将大(dà)模型比作(zuò)金(jīn)子,那麽鏟子是什(shén)麽呢(ne)?答(dá)案是算(suàn)力+推理(lǐ)服務,接下(xià)來(lái)我們來(lái)看(kàn)Tecorigin準備了(le)什(shén)麽樣的“鏟子”。
大(dà)模型推理(lǐ)核心技術
“
1
“
2
“
3
“
4
Large memory footprint(大(dà)量顯存開(kāi)銷),GPT/LLaMA等大(dà)模型的模型結構與解碼方式直接導緻了(le)在推理(lǐ)過程中會(huì)産生大(dà)量的顯存開(kāi)銷,由Parameter(參數)和(hé)Intermediate states(中間激活值)組成。
Low parallelizability(低(dī)并行度),當前主流自(zì)然語言模型均是Autoregressive(自(zì)回歸),這(zhè)種自(zì)回歸的模式導緻了(le)非常低(dī)的并行度。

圖9 大(dà)語言模型推理(lǐ)過程
基于以上(shàng)的目标和(hé)挑戰,爲了(le)更好(hǎo)的支持用(yòng)戶并提高(gāo)大(dà)模型推理(lǐ)性能(néng),Tecorigin從(cóng)下(xià)面幾方面入手。
Large 盡可能(néng)小(xiǎo)的Memory footprint
支持多種推理(lǐ)框架
基于不同的業務場景,需要靈活選擇一個合适的推理(lǐ)框架。當前比較主流的推理(lǐ)框架有vLLM,Fastertransformer+Triton Server,TGI(Text generation inference)等。
其中vLLM框架支持PagedAttention[3]和(hé)Continuous batching[4]等技術。
PagedAttention技術可以讓KV Cache通過固定大(dà)小(xiǎo)的“頁”來(lái)實現(xiàn)顯存的分配而不需要框架分配max_seq_len長度的連續内存,大(dà)大(dà)降低(dī)了(le)不必要的顯存開(kāi)銷,從(cóng)而極大(dà)的提升了(le)推理(lǐ)更大(dà)batch的可能(néng),這(zhè)意味着更高(gāo)的Throughput。
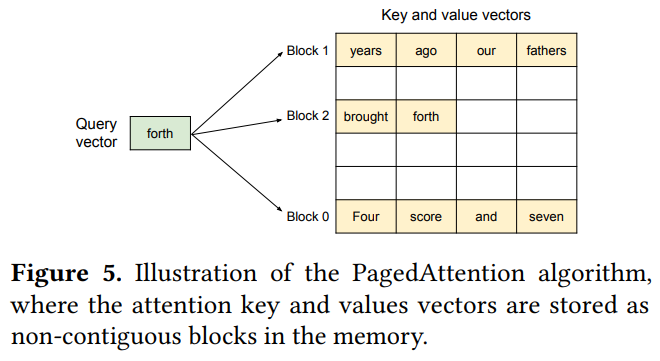
圖10 PagedAttention算(suàn)法示意,引用(yòng)自(zì)[4]
Continuous batching在進行batch>1的推理(lǐ)場景下(xià),一旦batch中的某一個序列推理(lǐ)完成,那麽就可以在之後插入一個新序列,從(cóng)而充分利用(yòng)GPU使用(yòng)率。
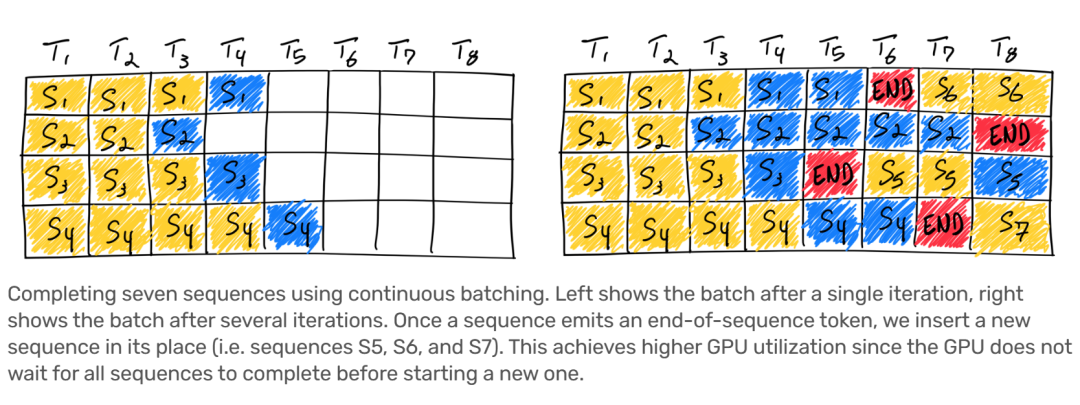
圖11 Continuous batching算(suàn)法示意,引用(yòng)自(zì)[5]
多卡模型并行推理(lǐ)
下(xià)圖展示了(le)基于模型并行的大(dà)模型推理(lǐ)切分方案,通過模型縱向切分,充分利用(yòng)多卡訪存/算(suàn)力,并深度優化通信算(suàn)子,高(gāo)效降低(dī)多卡并行推理(lǐ)帶來(lái)通信開(kāi)銷。
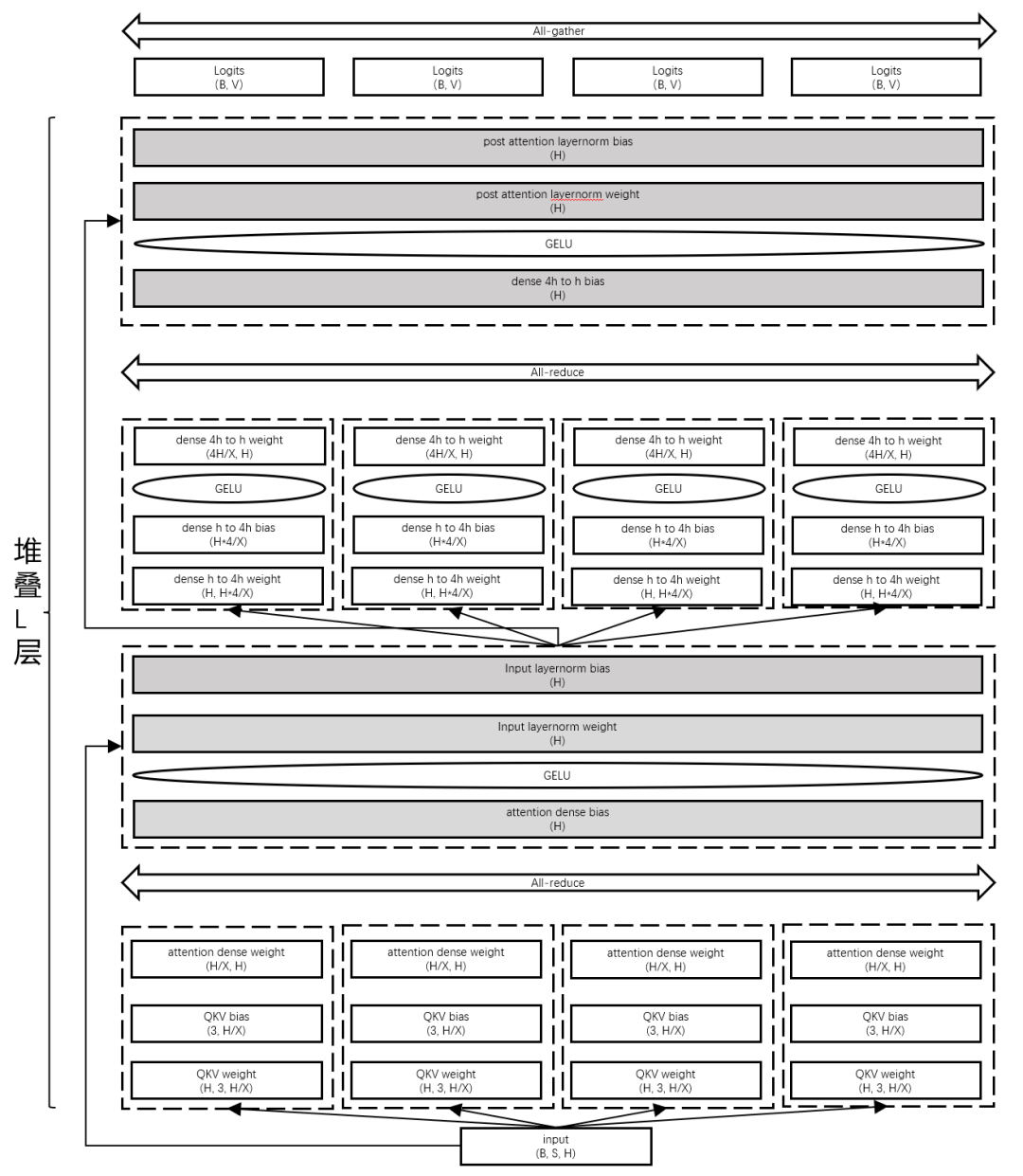
圖12 模型并行推理(lǐ)模型切分方案示意

同時(shí),我們也(yě)開(kāi)發了(le)Shard buffer、KV Cache等核心技術減少顯存開(kāi)銷和(hé)提高(gāo)推理(lǐ)性能(néng)。以此作(zuò)爲後端,前端接入了(le)vLLM/Triton Server等主流框架。
圖13 模型量化、模型蒸餾、模型剪枝算(suàn)法示意,來(lái)自(zì)網絡
GPTQ(weight only)
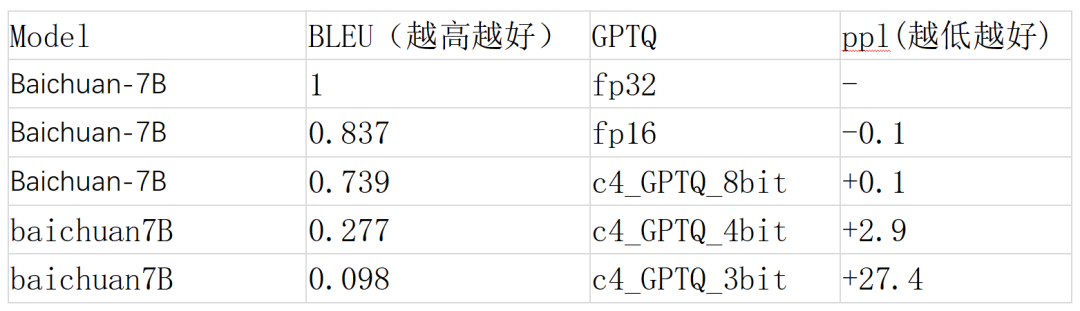
除此之外(wài)……
Low 盡可能(néng)高(gāo)的parallelizability
爲了(le)解決Low parallelizability,我們在8月份提出了(le)RecycleGPT[6],一種可重複利用(yòng)模型狀态加速解碼過程的模型,在近乎無效果損失的前提下(xià),實現(xiàn)了(le)1.4倍的推理(lǐ)加速,并引起了(le)廣泛關注。

圖14 RecycleGPT算(suàn)法示意
RecycleGPT[6]在傳統的自(zì)回歸語言模型基礎上(shàng)增加了(le)一個Recyclable Module(再利用(yòng)模塊)。這(zhè)個結構很(hěn)好(hǎo)的回收了(le)當前step輸出的隐狀态并再利用(yòng)于Next Next token(下(xià)下(xià)個令牌)生成。通過這(zhè)樣的方式提高(gāo)了(le)一次推理(lǐ)的利用(yòng)率,從(cóng)而端到(dào)端提升模型的推理(lǐ)性能(néng)。
圖15 RecycleGPT得到(dào)廣泛關注
至此,本文(wén)簡要介紹了(le)大(dà)語言模型的近3年發展現(xiàn)狀,以及大(dà)模型推理(lǐ)的核心挑戰及其對(duì)應的主流優化方案,并簡要介紹了(le)Tecorigin在大(dà)模型推理(lǐ)上(shàng)已有的技術能(néng)力,《大(dà)模型技術·起航&推理(lǐ)篇》到(dào)此結束。未來(lái),會(huì)有更多的大(dà)模型技術跟大(dà)家一起分享、交流、讨論。
入局者,厚積方可薄發。太初元碁Tecorigin将持續深耕産業創新沃土,與時(shí)代發展同頻共振,共育數智卓越人才,憑借深厚技術沉澱與領先研發實力,驅動算(suàn)力之輪駛向未來(lái)智能(néng)世界!
免費試用(yòng)申請(qǐng)
如果您對(duì)我們的産品感興趣,可點擊底部“閱讀原文(wén)”,進行試用(yòng)申請(qǐng);
或複制下(xià)方鏈接:https://shimo.im/forms/KrkElNNyO7uWeRqJ/fill 在浏覽器中打開(kāi),即可搶先試用(yòng)!
參考文(wén)獻
[1] [1706.03762] Attention Is All You Need (arxiv.org)
[2] [2303.18223] A Survey of Large Language Models (arxiv.org)
[3] [2108.07258] On the Opportunities and Risks of Foundation Models (arxiv.org)
[4] [2309.06180] Efficient Memory Management for Large Language Model Serving with PagedAttention (arxiv.org)
[5] Achieve 23x LLM Inference Throughput & Reduce p50 Latency (anyscale.com)
[6] [2308.03421] RecycleGPT: An Autoregressive Language Model with Recyclable Module (arxiv.org)
